篇首语:本文由编程笔记#小编为大家整理,主要介绍了《neural network and deep learning》题解——ch03 再看手写识别问题题解与源码分析相关的知识,希望对你有一定的参考价值。
http://blog.csdn.net/u011239443/article/details/77649026
完整代码:https://github.com/xiaoyesoso/neural-networks-and-deep-learning/blob/master/src/network2.py
我们之前根据《neural network and deep learning》题解——ch02 反向传播讲解了ch02 Network源码分析。这篇是对ch02 Network源码分析的改进。这里我们结合《机器学习技法》学习笔记12——神经网络重新讲解下。
class QuadraticCost(object):
@staticmethod
def fn(a, y):
return 0.5 * np.linalg.norm(a - y) ** 2
@staticmethod
def delta(z, a, y):
return (a - y) * sigmoid_prime(z)
class CrossEntropyCost(object):
@staticmethod
def fn(a, y):
return np.sum(np.nan_to_num(-y * np.log(a) - (1 - y) * np.log(1 - a)))
@staticmethod
def delta(z, a, y):
return (a - y)
这边我们把损失函数封装成两个类,静态函数 fn 返回的是损失,delta返回的是ch02 反向传播中的δ。该delta对应《机器学习技法》学习笔记12——神经网络中就是:
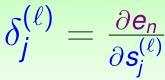
我们在Network中使用的就是二次代价函数,这里我们就只讲解另外的交叉熵代价函数:

对应代码:
np.sum(np.nan_to_num(-y * np.log(a) - (1 - y) * np.log(1 - a)))
接下来我们来看看关于delta的问题:
看看 network.py 中的 Network.cost_derivative ⽅法。这个⽅法是为⼆次代价函数写的。怎样修改可以⽤于交叉熵代价函数上?你能不能想到可能在交叉熵函数上遇到的问题?在 network2.py 中,我们已经去掉了Network.cost_derivative ⽅法,将其集成进了‘CrossEntropyCost.delta‘ ⽅法中。请问,这样是如何解决你已经发现的问题的?
对应《机器学习技法》学习笔记12——神经网络中,cost_derivative就是
∂
e
n
∂
x
L
∂\\frace_n∂x^L
∂∂xLen,有链式法则得到:
δ
L
=
∂
e
n
∂
x
L
∂
x
L
∂
s
L
\\large δ^L = \\frac∂e_n∂x^L\\frac∂x^L∂s^L
δL=∂xL∂en∂sL∂xL
network中也是的cost_derivative也是用在求δ。
而CrossEntropyCost.delta是:
return (a - y)
代码 中的 a 就是上式中的x,z 就是上式中的 s。
我们对CrossEntropyCost关于a求导,得到:
−
(
y
a
−
1
−
y
1
−
a
)
=
−
y
(
1
−
a
)
+
a
(
1
−
y
)
a
(
1
−
a
)
=
−
y
+
a
a
(
1
−
a
)
\\large -(\\fracya - \\frac1-y1-a) = \\frac-y(1-a) + a(1- y)a(1-a) = \\frac-y+aa(1-a)
−(ay−1−a1−y)=a(1−a)−y(1−a)+a(1−y)=a(1−a)−y+a
所以 CrossEntropyCost 的 cost_derivative 是
−
y
+
a
a
(
1
−
a
)
\\frac-y+aa(1-a)
a(1−a)−y+a
由 http://blog.csdn.net/u011239443/article/details/75091283#t0 可知:
∂
a
∂
z
=
a
(
1
−
a
)
\\large \\frac∂a∂z = a(1-a)
∂z∂a=a(1−a)
所以:
δ
=
∂
e
n
∂
a
∂
a
∂
z
=
−
y
+
a
a
(
1
−
a
)
a
(
1
−
a
)
=
a
−
y
\\large δ = \\frac∂e_n∂a\\frac∂a∂z = \\frac-y+aa(1-a)a(1-a) = a - y
δ=∂a∂en∂z∂a=a(1−a)−y+aa(1−a)=a−y
和Network基本上一样,只不过封装成了一个default_weight_initializer函数
def __init__(self, sizes, cost=CrossEntropyCost):
self.num_layers = len(sizes)
self.sizes = sizes
self.default_weight_initializer()
self.cost = cost
def default_weight_initializer(self):
self.biases = [np.random.rand(y, 1) for y in self.sizes[1:]]
self.weights = [np.random.rand(y, x) / np.sqrt(x) for x, y in zip(self.sizes[:-1], self.sizes[1:])]
随机梯度下降
和Network基本上一样,各个monitor是代表是否需要检测该对应的指标。
def SGD(self, training_data, epochs, mini_batch_size, eta,
lmbda=0.0,
evaluation_data=None,
monitor_evaluation_cost=False,
monitor_evaluation_accuracy=False,
monitor_training_cost=False,
monitor_training_accuray=False):
if evaluation_data:
n_data = len(evaluation_data)
n = len(training_data)
evaluation_cost, evaluation_accurary = [], []
training_cost, training_accuray = [], []
for j in xrange(epochs):
random.shuffle(training_data)
mini_batches = [training_data[k:k + mini_batch_size] for k in range(0, n, mini_batch_size)]
for mini_batch in mini_batches:
self.update_mini_batch(mini_batch, eta, lmbda, len(training_data))
print "Epoch %s training complete" %(j+1)
if monitor_training_cost:
cost = self.total_cost(training_data, lmbda)
training_cost.append(cost)
print "Cost on train: ".format(cost)
if monitor_training_accuray:
acc = self.accuracy(training_data,covert=True)
training_accuray.append(acc)
print "Acc on train: / ".format(acc,n)
if monitor_evaluation_cost:
cost = self.total_cost(evaluation_data, lmbda,convert=True)
evaluation_cost.append(cost)
print "Cost on evaluation: ".format(cost)
if monitor_evaluation_accuracy:
acc = self.accuracy(evaluation_data)
evaluation_accurary.append(acc)
print "Acc on evaluation: / ".format(acc, n_data)
print
return evaluation_cost,evaluation_accurary,training_cost,training_accuray
反向传播
def backprop(self, x, y):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
activation = x
activations = [x]
zs = []
for b, w in zip(self.biases, self.weights):
z = np.dot(w, activation) + b
zs.append(z)
activation = sigmoid(z)
activations.append(activation)
delta = (self.cost).delta(zs[-1], activations[-1], y)
nabla_b[-1] = delta
nabla_w[-1] = np.dot(delta, activations[-2].transpose())
for l in xrange(2, self.num_layers):
z = zs[-l]
sp = sigmoid_prime(z)
delta = np.dot(self.weights[-l + 1].transpose(), delta) * sp
nabla_b[-l] = delta
nabla_w[-l] = np.dot(delta, activations[-l - 1].transpose())
return (nabla_b, nabla_w)
def update_mini_batch(self, mini_batch, eta, lmbda, n):
nabla_b = [np.zeros(b.shape) for b in self.biases]
nabla_w = [np.zeros(w.shape) for w in self.weights]
for x, y in mini_batch:
delta_nabla_b, delta_nabla_w = self.backprop(x, y)
nabla_b = [nb + dnb for nb, dnb in zip(nabla_b, delta_nabla_b)]
nabla_w = [nw + dnw for nw, dnw in zip(nabla_w, delta_nabla_w)]
self.weights = [(1 - eta * (lmbda / n)) * w - (eta / len(mini_batch)) * nw for w, nw in
zip(self.weights, nabla_w)]
self.biases = [b - (eta / len(mini_batch)) * nb for b, nb in zip(self.biases, nabla_b)]
我们可以看到基本上和Network中一样,前面已经讲解过δ。这里的代码也可以和《机器学习技法》学习笔记12——神经网络中的公式对应:

主要区别是在最后两行更新的时候加入了L2规范化:
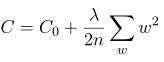
求偏导数得:

则:

这里引出了我们这节的另外一个问题:
更改上⾯的代码来实现 L1 规范化

求导得到:
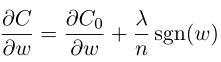

则:
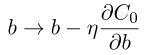

对应的代码应该写为:
self.weights = [(1 - eta * (lmbda / n)*np.sign(w)) * w - (eta / len(mini_batch)) * nw for w, nw in
zip(self.weights, nabla_w)
var cpro_id = "u6885494";








 京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有
京公网安备 11010802041100号 | 京ICP备19059560号-4 | PHP1.CN 第一PHP社区 版权所有